SPARC Open Dataset Structure
How are SPARC datasets structured on AWS S3?
When SPARC datasets are published, a snapshot of the dataset is copied to a public AWS S3 bucket. The structure of the published datasets follows both Pennsieve Public Dataset Structure and embedded within this structure, the data is organized according to the SPARC Dataset Standard.
Pennsieve Public Dataset Structure
The Pennsieve Public Dataset standard ensures that all published datasets are serialized to AWS S3 in a consistent and machine readable way. Datasets on Pennsieve include both uploaded files, and a user-defined graph-based metadata store. When datasets are published, both files and metadata are exported and serialized into S3 assets in a standardized way.
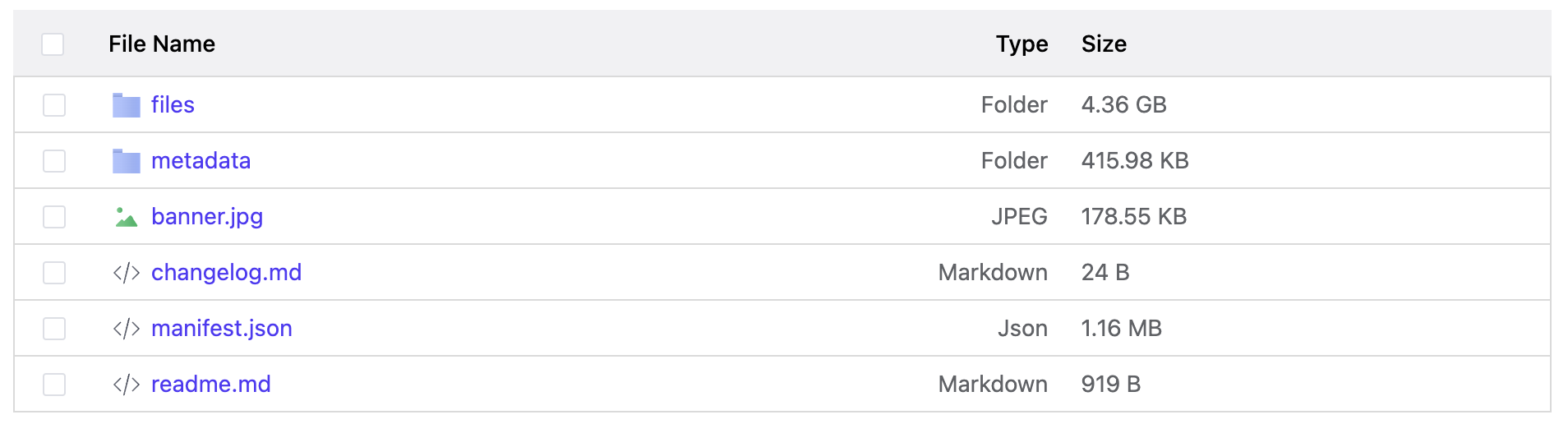
- The metadata graph is exported as a set of CSV files representing the different node-types and relationships. These files are available in the
metadatafolder in the published dataset. - All uploaded files in a dataset are exported to S3 where the S3 prefix matches the path to the uploaded files. All uploaded files in a dataset are exported to the
filesfolder in the published dataset. - A set of additional dataset related files are stored in the root folder of the published dataset including: 1) a banner image representing the dataset, 2) a
changelog.mdfile that indicates changes between versions of published datasets, 3)readme.mdwith a description of the dataset and 4) a manifest.json file which details the structure of the dataset. Detailed information about the exported file-structure and the manifest.json file can be found here: https://docs.pennsieve.io/docs/data-publishing-standard
SPARC Dataset Structure (SDS)
Within the files folder, all SPARC datasets follow the SPARC Dataset Standard (SDS). The SDS dictates the organizational structure of the user-uploaded files within a dataset and how metadata related to samples and subjects should be included as part of the dataset.
Detailed information about the SDS can be found in the following document: SPARC Dataset Structure (SDS). Please note that
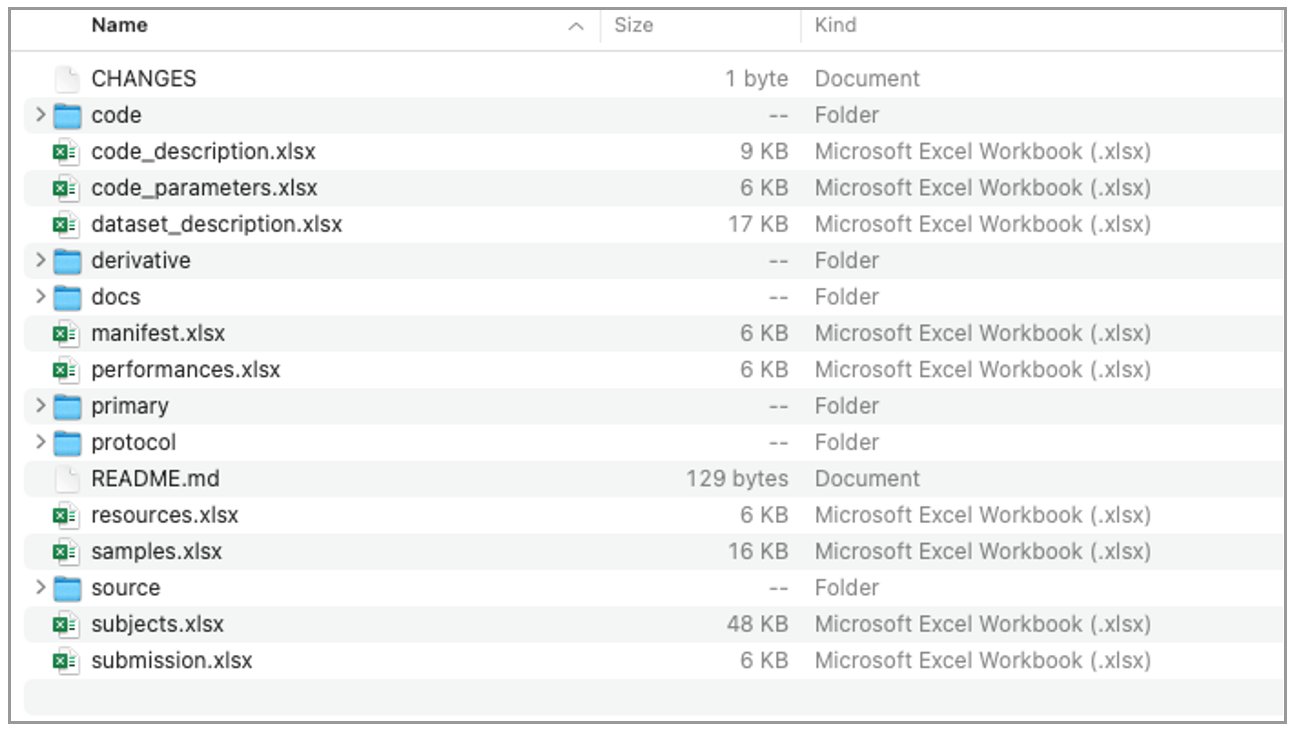
Example of a dataset organized according to the SPARC Dataset Standard (v2.0). Data is separated between Primary, and Derivative data, protocols, and documentation.
Updated about 1 year ago