SPARC Portal Data Repository Structure
Dataset storage: what is the difference between the SPARC Portal and Pennsieve?
The SPARC Portal Structure Overview
Together, the SPARC DRC has leveraged their individual Core resources, services, and collaborative relationships to build the SPARC Portal along with an ecosystem of resources for the peripheral nervous system (PNS) and a community for its researchers. The SPARC Portal provides the point of entry to SPARC's publicly available data, maps and computational tools. But behind the scenes are the tools that enable data upload, management, curation and private sharing. Read on to learn how pieces fit together to deliver the high quality, FAIR data that has become synonymous with SPARC.
SPARC Data Management - private and public sharing
Before datasets are Published to the SPARC Portal for public access, SPARC provides tools and resources for our data contributors to upload and curate datasets to meet the SPARC Standards, and to share datasets privately with select users. Learn more about the SPARC data submission process supported by the SPARC Curation Team.
After datasets are curated to meet the SPARC standards and are ready to be shared publicly, they are Published to the SPARC Portal for public users to interact with using the SPARC Apps and other Features.
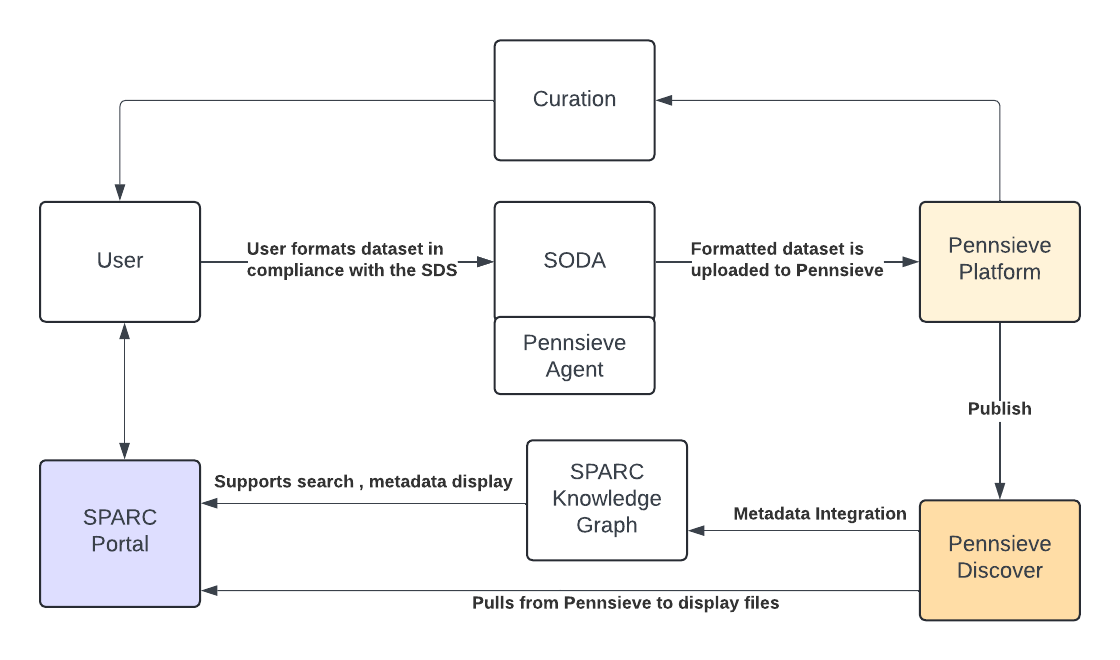
SPARC Data Management Tools
SPARC uses Pennsieve to provide its core repository functionality for storing, managing, privately sharing, and publishing SPARC datasets to the SPARC Portal for public access.
Pennsieve
The SPARC DRC Data Coordination Core (DAT-Core) is the team behind the Pennsieve Data Ecosystem - a cloud-based scientific data management platform focused on integrating complex datasets, fostering collaboration and publishing scientific data according to all FAIR Data Principles. Pennsieve is just one part of the SPARC Data Ecosystem. Pennsieve also supports multiple data repositories, private research labs, and other organizations through a single set of services. This multi-tenant approach enables these different stakeholders to utilize the same infrastructure to set up a repository and data management solution without having to set up the infrastructure for each project independently. Learn more about Pennsieve in their Documentation Hub.
Pennsieve is developed as an open-source platform, making its API publicly accessible. This allows anyone to build applications that use the Pennsieve Data Ecosystem under the hood. Pennsieve provides two applications and a rich set of APIs, offering users flexible mechanisms to support all kinds of data sharing and to interact with public datasets. SPARC uses Pennsieve's APIs to build specialized tools, like SODA and the SPARC Portal.
Pennsieve Platform for private data sharing
The Pennsieve data management platform is the web application found at https://app.pennsieve.io. SPARC supported consortia and dataset contributors have access to specialized workspaces for private data sharing and curation. This is where SPARC data contributors create datasets, upload data, share data with collaborators, and curate datasets before publishing them publicly.
Pennsieve Discover for public sharing
Pennsieve Discover is the public-facing web application found at https://discover.pennsieve.io. It provides a way for anyone to find all datasets published across all repositories supported by the Pennsieve Data Ecosystem.
SODA for SPARC
One of SPARC's greatest assets is the SPARC Knowledge Graph, which is what links and integrates data, models, metadata, and standards. The SPARC DRC's Knowledge Management Core (K-Core) oversees the implementation of SPARC Standards, from establishing and maintaining standards to providing the SPARC Curation Team, who support users in organizing their datasets to meet them, and providing the validation processes to ensure the quality of the datasets are at their highest. The utility of the SPARC Knowledge Graph starts with high quality, standardized datasets achieved through the SPARC Standards and curation.
K-Core teamed up with The FAIR Data Innovations Hub team at the California Medical Innovations Institute, to create SODA, a desktop application (SODA for SPARC) that simplifies organizing and uploading SPARC datasets to the Pennsieve platform for publication to the SPARC Portal. Learn more about how SODA became an integral part of SPARC.
SODA utilizes the public APIs from Pennsieve and various other applications to facilitate and automate data curation, upload and validation.
SPARC Portal
Built by the SPARC DRC, the SPARC Portal (sparc.science) is the hub of the SPARC Data Ecosystem. This public-facing web application built specifically to surface datasets curated to the SPARC standards to be surfaced from Pennsieve Discover for users to interact with using the other specialized applications, tools, and resources available through the SPARC Portal. In addition to hosting public SPARC datasets, the Portal is also the seat of the SPARC community, where you can find information about SPARC events, news, and opportunities for the PNS community to collaborate.
What is the difference between SPARC and Pennsieve?
- Pennsieve is just one part of the SPARC Data Ecosystem. The SPARC DRC's DAT-Core is the team that interfaces between Pennsieve and SPARC.
- SPARC's mission and vision focuses on "Bridging the Body and the Brain" by supporting data integration within the domain of the peripheral nervous system
- SPARC Standards set SPARC datasets apart from other Pennsieve repositories, providing professional curation, knowledge management, and integration through interactions with other SPARC Applications, like functional and connectivity mapping through MAP-Core and computational modeling through SIM-Core.
Updated 11 months ago