Publishing and Versioning
need text describing the publishing and versioning capabilities and link to changes in public dataset policy
needs to be updated 4/30/2025 Jacqueline
good text to use in other sections
Publishing with SPARC Benefits Submitters and Visitors
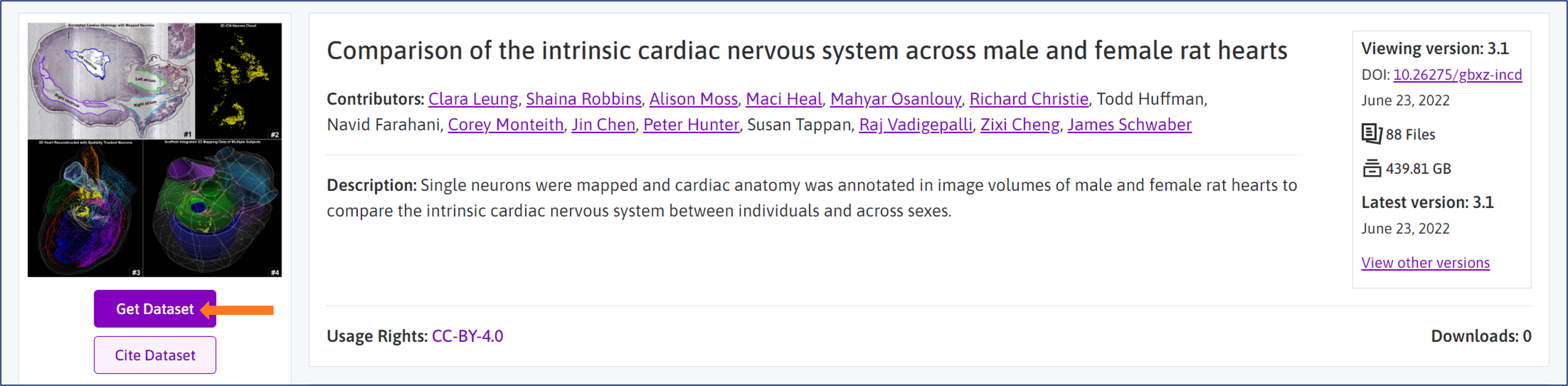
SPARC is a versatile and collaborative platform designed to support researchers working with multi-modal datasets, from gigabytes to terabytes in size. Publishing through SPARC includes numerous advantages for both contributors and those interested in referencing or using research assets shared on the Portal (see Figures 4 and 5 for additional details).
SPARC has high-standards for publishing on the Portal, and our professional Curation team guides investigators through the process, resulting in a well-structured dataset or model with its own landing page, DOI, and associated protocols. Products published on the Portal are highlighted with a number of other features that aid understandability of both the experiment and the dataset or model. This arms visitors with information to help them determine if they wish to use it or even pursue a collaboration. Moreover, this high-quality, structured format, with rich associated metadata and protocols aid artificial intelligence (AI) readiness.
Figure 4. Assets published on the SPARC Portal have a long list of advantages that promote FAIR. Each has its own landing page, citable DOI, and information about the authors and experiment that aid understandability, reuse, and collaboration. Visitors are able to navigate versions, the license, how to cite it, and usage metrics. Files can be downloaded directly from the Portal or for larger files through AWS. Dataset displayed: [2]
The publishing process (Figure 6) exports the files, folder structure, and metadata graph as a set of Comma Separated Files (CSV) and a JSON-based manifest of all assets in the published dataset. This exported dataset is available on a publicly accessible AWS S3 bucket, allowing anyone to access the data directly in the cloud using standard AWS tools. For smaller datasets, Pennsieve provides functionality to download a complete dataset (or individual files) as a ZIP archive (up to 15GB) at no cost. Users can use command line tools to download the data directly from AWS for larger datasets. Pennsieve has leveraged NIH Strides to accommodate data storage, but has recently initiated the transition to using the AWS Open Data Sponsorship program to host public data on the SPARC Portal as the NIH STRIDES program sponsorship is slated to be terminated in September 2025. The AWS Open Data Sponsorship program ensures that public datasets remain available at no cost to the user. The file structure of the published dataset and the JSON-based manifest is optimized for repository crawlers to find, index, and reference all relevant information in the dataset. This effort improves the AI-readiness of the datasets and supports the broad availability and findability of the deposited data and knowledge.
The storage mechanism for published datasets has been enhanced to reduce file duplication, significantly lower storage costs, and improve the sustainability of the SPARC resource. This improved workflow ensures that published files are stored only once in the cloud, offering on-demand access to older versions of datasets. Users can automatically access the latest version of a published dataset on AWS, ensuring they always see the most current files and versions. For any dataset size, users can request the platform to recreate and provide access to an older version on AWS S3. Once the older version is ready, users will be notified and given instructions on how to access it on AWS S3. The older dataset will be available temporarily and will be removed after a specified period.
Updated about 1 year ago